




Groq 推出了 Llama-3 Tool Use 8B 和 70B 模型
最近 Groq 宣布发布两个专门用于工具使用的新开源模型:Llama-3-Groq-70B-Tool-Use 和 Llama-3-Groq-8B-Tool-Use,这些模型是基于 Meta Llama-3 构建的。 这些模型由 Glaive 合作开发。
在 Berkeley 函数调用排行榜 (BFCL) 上,Llama-3-Groq-70B-Tool-Use 是当前性能最高的模型,超越了所有其他开源和专有模型。
模型详情
- 可用性:这两个模型现在已在 GroqCloud™ Developer Hub 和 Hugging Face 上上线:
- 许可:这些模型是以与原始 Llama-3 模型相同的宽松许可证发布的。
- 训练方法:结合了全量微调和直接偏好优化 (Direct Preference Optimization, DPO) 来实现顶级的工具使用性能。 训练过程中未使用任何用户数据,仅采用了合乎伦理的生成数据。
基准测试结果
在具备工具使用能力的大语言模型方面设立了新的基准:
- Llama-3-Groq-70B-Tool-Use:总体准确率达 90.76%(在发表时在 BFCL 上排名第一)
- Llama-3-Groq-8B-Tool-Use:总体准确率达 89.06%(在发表时在 BFCL 上排名第三)
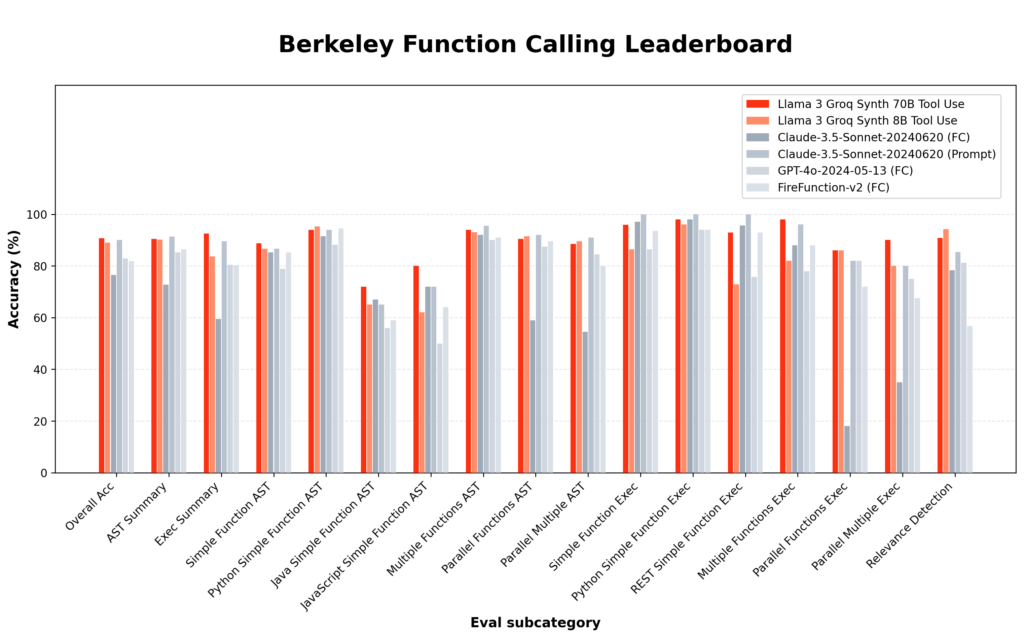
基准测试结果是在提交7bef000时,通过运行开源评估库 ShishirPatil/gorilla达到的。
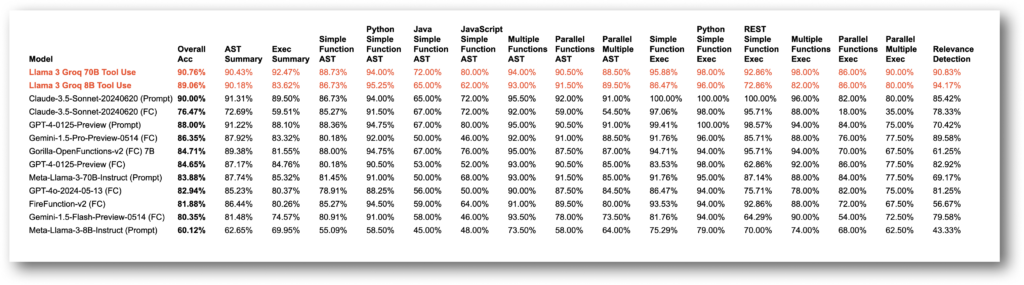
与其他模型的详细性能比较如下:
过拟合
按照 LMSYS 方法进行了全面的污染分析,详细过程在其 博客文章中有描述。结果显示,他们用来进行微调的合成数据污染率很低:相对于 BFCL 测试集数据,训练的 SFT 数据仅有 5.6%,DPO 数据则只有 1.3%。这表明,在评估基准上几乎没有发生过拟合。
一般基准性能
精心设计的学习计划,尽量减少对通用性能的影响。

专项模型与路由
虽然 Llama-3 Groq Tool Use 模型在函数调用和工具使用方面表现出色,但推荐采用一种将这些专用模型与通用语言模型相结合的混合方法。这样能够充分发挥两种模型的优势,从而优化各种任务的性能。
推荐方法:
- 查询分析: 建立一个路由系统,分析用户的查询,确定其性质和需求。
- 模型选择: 根据查询分析结果,将请求分配给最合适的模型:
- 对于涉及函数调用、API 交互或结构化数据操作的查询,使用 Llama-3 Groq Tool Use 模型。
- 对于一般知识、开放性对话或与工具使用无关的任务,使用未修改的 Llama-3 70B 等通用语言模型。
通过这种路由策略,可以确保每个查询都由最适合的模型处理,从而最大化 AI 系统的整体性能和能力。这样既可以利用 Llama-3 Groq 模型的专业工具使用能力,又能保持通用模型的灵活性和广泛的知识基础。
Llama-3-Groq-70B-Tool-Use 和 Llama-3-Groq-8B-Tool-Use 目前可以通过 Groq API 使用以下模型 ID 进行使用:
- llama3-groq-70b-8192-tool-use-preview
- llama3-groq-8b-8192-tool-use-preview